今年,GPT、AI绘画等人工智能大模型工具火热,许多人也想来追一波AI创业热潮,相关创业项目层出不穷。优质数据对AI大模型训练至关重要,只有拥有足够多的数据,才能训练出智能、强大的AI工具。我国互联网蓬勃发展二十余年,还能缺少数据?这不,曼昆律师最近接到网友咨询,准备用爬虫爬取知乎数据,做一个知乎GPT机器人岂不美哉?且慢,这其中的法律风险不可忽视。
01 爬虫是把双刃剑
爬虫技术是一种通过编程自动从互联网上获取数据的技术。它的名字形象、生动地表明了它的工作原理:模拟人类在网页浏览器中浏览网页的过程,进行数据采集和数据抓取。
网络爬虫广泛应用于搜索引擎、数据采集、广告过滤、大数据分析等领域。作为一种功能强大的信息采集程序,它能够显著提高工作效率,尤其是对海量数据的收集和整理。
经济日报:AIGC有规范才有美好未来:4月16日消息,据经济日报文章指出,对AIGC这样快速发展的新技术新应用来说,各类风险显而易见,入局企业尤其担心重金投入后遭遇政策风险导致投资损失。
首个AIGC管理办法公开征求意见,本身就是一个重大信号,说明我国非常重视此轮AI发展所引领的科技变革,期待促进AIGC技术的健康发展。
与新技术开发几乎同步的监管规范,必将随着技术发展和时代变迁而更新调整。此次AIGC管理办法的征求意见稿是开局的第一步,它将促进AIGC产业健康可持续发展。无规矩不成方圆,AIGC有规范才有美好未来。?[2023/4/16 14:06:38]
然而,一旦技术被不正当使用,也会引发“虫灾”,导致网络拥堵、崩溃、服务器瘫痪甚至引发数据安全风险。我们熟悉的“裁判文书网”也不能幸免:
NFT项目DigiDaigaku官方空投将于本周五发布:8月29日消息,NFT项目DigiDaigaku母公司LimitBreak首席执行官GabrielLeydon发文表示,DigiDaigaku的官方空投将于本周五发布,本周将释出更多细节。此前GabrielLeydon于8月22日在个人社交媒体平台发起关于DigiDaigaku接下来能为社区做什么投票,其中空投以59.1%支持率胜出。[2022/8/30 12:56:23]

图:2019年,最高人民法院发布的《关于“中国裁判文书网”网站建设建议的答复》
02 使用爬虫技术的风险
澳本聪Craig Wright称中本聪从未登录Bitcointalk 论坛:澳本聪Craig Wright最近称,中本聪从未登录使用过论坛Bitcointalk。该网站是已知最早的比特币论坛之一,并且有许多帖子来自声称是Satoshi的帐户。Wright称中本聪未使用该平台进行交流,他说中本聪使用该网站是一个“神话”。
“这是一个神话,Bitcointalk上Satoshi的账号是我的,上面所有帖子实际上都是我发的,并且未被编辑或更改,并且网站登录名属于我”。(Bitcoin.com)[2020/4/28]
爬虫作为一项获取数据的技术手段,并未被法律禁止。但使用方式及使用目的决定了是否会产生违法的行为和后果。
使用爬虫技术, 能在短时间内对网站进行大量访问,频繁抓取页面和数据。这可能会导致网站的带宽和服务器负载急剧增加,从而影响网站的正常运行,甚至导致宕机或响应缓慢,干扰被访问网站的正常运营,严重时可构成犯罪。
声音 | Craig Wright:任何包含DSV的交易都是违法的:据Ambcrypto消息,Craig Wright最近出现在由比特币支持者Tone Vays主持的视频上,谈论即将于11月举行的即将到来的硬叉。 Wright表示,比特币的原始版本没有块大小,它在最初阶段没有经济价值。DSV改变了一切,任何包含DSV的交易都是违法的。[2018/11/13]
杨某授权公司员工张某开发某信贷系统软件,该软件内的“网络爬虫"功能能与深圳市居住证网站链接。2018年5月,该软件连续两小时对深圳市居住证系统查询大量访问,致使深圳市居住证系统无法正常运作,极大地影响了该居住证系统使用方深圳市局人口管理处的日常运作。二人均构成破坏计算机信息系统罪。【(2019)粤0305刑初193号】
与使用方式相比,如何使用爬取的信息和数据,对爬虫行为的定性影响更大。
Craig Wright已收到因盗取已故IT专家Dave Kleiman价值百亿美元比特币的传票:据ccn报道,自称比特币创始人的Craig Wright已收到官方传票,因其盗窃早期比特币采纳者Dave Kleiman的100亿美元比特币。目前居住海外的Wright必须在4月16日之前回复传票;。其原本需要在更早作出回应,法院曾授予他延期。法院文件还显示,律师Andres Rivero曾前几次听证会中代表他,但他本人和律师都没有公开处理这件诉讼。昨日在东京举行的论坛上,以太坊创始人V神称其为子。[2018/4/5]
非法使用爬取的数据和信息主要有:
(1)盗取个人信息:使用爬虫技术恶意抓取网站上的个人信息,可能涉及侵犯他人隐私、个人信息,严重可构成侵犯公民个人信息罪。

(2)商业竞争中的不正当行为:使用爬虫技术获取竞争对手的商业秘密、定价信息、用户数据等,对数据整合后“搬家”到其他平台,通过这种便捷的方式获取大量有价值的数据、信息,以谋取不正当竞争优势。
在“酷米客诉车来不正当竞争纠纷案”中,法院认为,未经权利人许可,利用网络爬虫技术进入权利人的服务器后台的方式非法获取并无偿使用权利人的实时公交信息数据的行为,实为一种“不劳而获”、“食人而肥”的行为,且具有非法占用他人无形财产权益,破坏他人市场竞争优势,构成不正当竞争。
(3)侵犯知识产权:爬取受版权保护的内容,然后用于未经授权的公开传播或商业用途,属于侵犯知识产权的行为。


03 爬虫数据“投喂”大模型的风险
通过前面的分析可知,使用爬虫技术的风险主要在于爬取的方式以及爬取的内容,那是不是控制爬取的频率和内容,爬取公开内容,用来训练机器人就没有什么风险了呢?
首先,知乎官方账号早在2018年就发布了《关于知乎用户权益保护升级的公告》,提到:知乎对第三方开放知乎内容的使用采取白名单制,第三方需要通过官方合作渠道进行申请。如果爬取行为违反了知乎的服务条款,知乎可能采取封禁账号、IP地址或者其他法律行动。
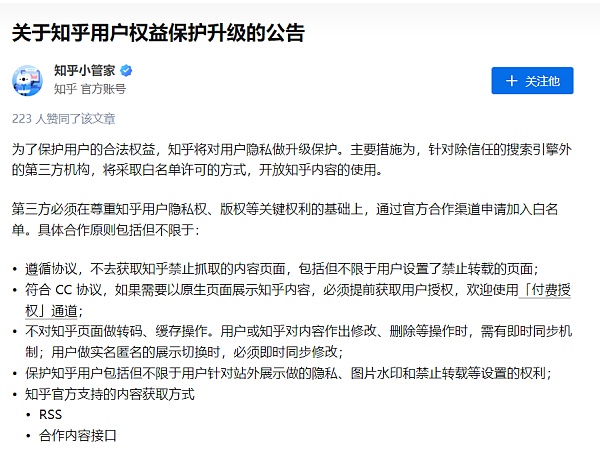
摘自《知乎机构号使用规范》(试行)
其次,知乎上的内容通常由用户原创或授权发布,著作权归用户本人所有。未经授权地爬取和使用这些内容,可能涉及侵犯知乎的版权和著作权。
其实,训练AI大模型,“数据盗窃”并非个案。上个月,笔神作文公开指控昔日合作伙伴学而思,认为学而思通过爬虫方式“偷数据”训练自家AI产品。笔神作文表示,将通过司法程序解决纠纷,要求“学而思”支付1元赔偿金,公开道歉,并删除已爬取的数据。
04 小结
在人工智能创业的热潮中,数据变得越来越重要。在面对爬虫技术带来的诱惑时,应当认识到,虽然爬虫技术本身并未被禁止,但其不当使用可能导致法律问题,尤其是在涉及个人信息、隐私、版权和不正当竞争等方面。
《生成式人工智能服务管理暂行办法》中明确提到,训练数据处理活动时,应当使用具有合法来源的数据和基础模型。各位老板在创业过程中,要确保数据采集的合法性和道德性。如果想要使用爬取的数据训练AI大模型,务必事先获得数据来源方的授权,并遵守相关平台的规定。
刘红林律师
个人专栏
阅读更多
Foresight News
金色财经 Jason.
白话区块链
金色早8点
LD Capital
-R3PO
MarsBit
深潮TechFlow
郑重声明: 本文版权归原作者所有, 转载文章仅为传播更多信息之目的, 如作者信息标记有误, 请第一时间联系我们修改或删除, 多谢。